TL;DR
Problem: Months-long deploys due to manual business-rule checks and low trust.
Solution: One-week CI/CD (after resolving permissions delays) with automated business-rule checks and gated promotion (feat/* → dev → prod → main).
Impact: Deploy in weeks, scale to 3+ models, restore stakeholder confidence, protect $1.9M churn.
When I joined the client, they were developing a churn prediction model to safeguard $1.9M in monthly recurring revenue. However, their deployment process was slow and error-prone, leading to trust issues among stakeholders. Here’s how a week’s project transformed my client team’s efficiency, scale and trust.
The Problem: Months Long Deployment Process
Imagine working on a model for multiple weeks, pushing a model update, only for manual business rules validations to halt deployment for months. The process would not scale as the team had planned to add more models in the next quarter.
The impact? Data scientists stuck on deployment instead of focusing on improving $1.9M monthly churn insights.
The Solution: Automated CI/CD Pipeline with Approval Gates
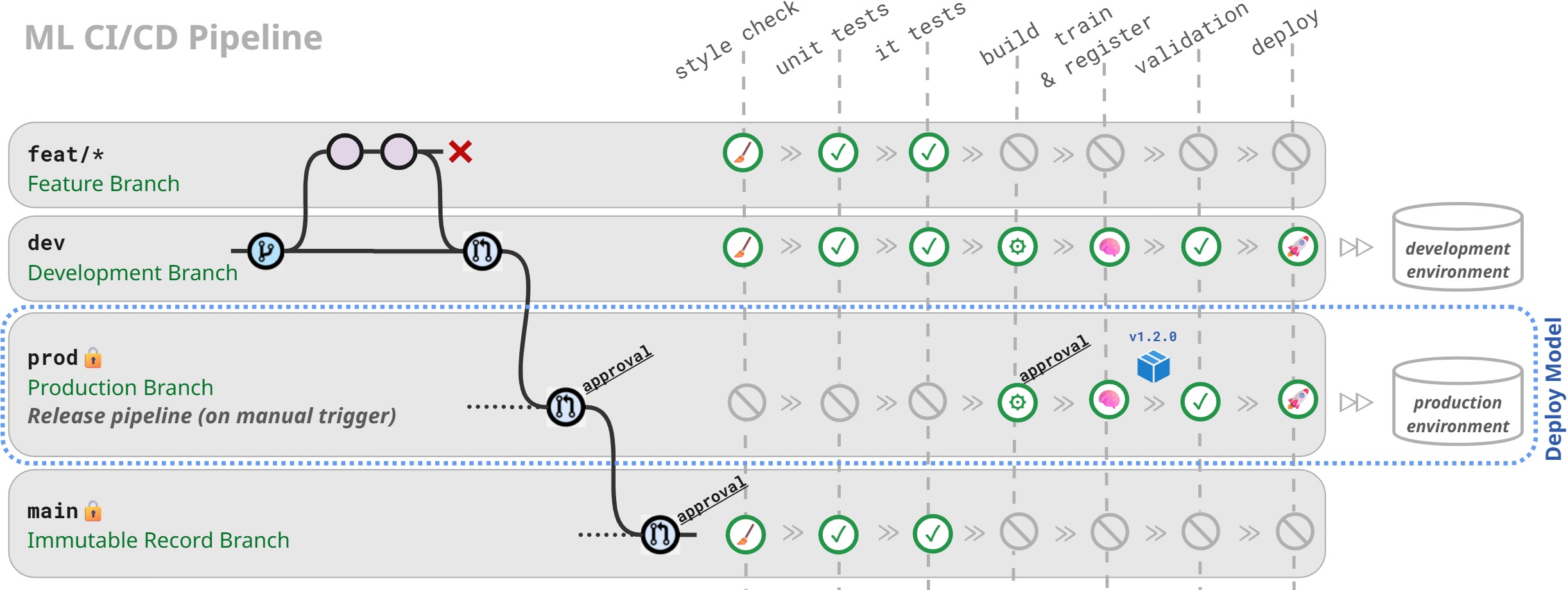
To address the manual bottlenecks and trust issues, I designed and implemented a complete CI/CD pipeline in just one week, tailored for a solo developer while enabling scalability to 3+ models. It ensures compliance with business rules. Here’s how it works in three key phases:
1. Automation
Core CI/CD Pipeline Stages:
- Tests (Unit & Integration): Automated pytest runs for code functionality and input/output checks, catching errors early.
- Build & Train: Packages the model code and automates training/registration in a Model Registry.
- Validation: Runs business rules like, failing the pipeline if thresholds aren’t met - eliminating manual business rules validations work. See Appendix A for YAML snippet.
- Deploy: Deploys to dev environment only if all prior stages pass.
The Release Pipeline requires manual approval gate to ensure only vetted models reach production. Stages:
- Build & Train: Packages the model code and automates training/registration with proper versioning (explained in Section 3).
- Validation.
- Deploy: Deploys to prod environment only if all prior stages pass.
2. Promotion control
Adopted a GitOps flow (feat/* → dev → prod → main) to isolate environments and reusable across multiple models:
- feat/* → dev: Auto-deploys to dev environment after push/merge and successful CI/CD.
- dev → prod: Requires PR merge with 1 approver, triggering manual release pipeline for promotion to prod environment.
- prod → main: Final PR merge (1 approver) archives as immutable record for rollback. If there are issues in prod, there’s an easy rollback.
3. Versioning
Implemented semantic versioning (MAJOR.MINOR.PATCH) for models, ensuring clear tracking of changes and audits across environments. See Appendix B for examples.
Overcoming Permissions Bottlenecks
What started as a straightforward infrastructure setup turned into a frustrating delay: the team responsible for granting permissions was overwhelmed with projects, leaving my requests unanswered for over a month. This stalled the CI/CD rollout twice, threatening deadlines.
I escalated to my manager, who intervened to prioritize the request. Within days, permissions were granted, allowing me to complete the pipeline in time.
Building Trust Through Cross-Team Debugging
Midway through testing the CI/CD pipeline, the training data retrieval failed due to a missing column in the Data Engineering team’s view. Their repo showed the column present, but runtime execution omitted it - a classic integration mismatch that could have derailed the entire project.
Rather than pointing fingers, I debugged the error myself, traced it to their deployment process, and provided step-by-step instructions. The DE team fixed it in just a couple of hours, restoring flow. This collaboration highlighted CI/CD’s value in catching data issues early through automated integration tests, preventing similar pitfalls in future deploys.
This setup required minimal code changes, reducing risks while scaling efficiently for additional models.
Governance & Collaboration
I proactively added a monthly monitoring notebook that flags data drift (e.g., PSI metrics showing moderate/high drift in average scores over an historical period), helping us safeguard churn predictions without manual overhauls. See Appendix D for an example.
I introduced documentation mapping every model version to its owner and documenting which versions were approved for production use. This eliminated ambiguity across teams and created a single source of truth for model governance.
The documentation also records release date, feature changes, training window, model performance, training time, and release notes for each version.
To ensure reproducibility and accelerate onboarding, I designed visual diagrams of the CI/CD pipeline, including validation logic, so engineers and stakeholders could understand the flow at a glance and adopt it consistently.
I clarified ownership of the dashboard where the model predictions were shown and documented the DE team data sources, establishing accountability.
I established an experiment registry capturing hypotheses, results, and decisions. This prevented repeated mistakes, accelerated informed iteration, and created an auditable trail of model development choices.
The Results: From Chaos to Confidence
The impact was immediate and measurable:
| Metric | Before | After |
|---|---|---|
| Model Deployment Time | Months | Weeks |
| Model Governance | Ad-hoc | Owners + Auditable trail |
| Onboarding Effort | High | Documented, visual, faster |
| Model Scalability | 1 model | 3+ models |
Business Impact
- Caught business rules issues pre-deployment, restoring stakeholder confidence.
- Safeguarded $1.9M monthly predictions.
- Reusable infrastructure scales to new models.
Key Learnings
- Prioritize automation for critical business checks to protect revenue goals.
- Design for scale and audit from day one.
- Balance speed with gates to ensure safe promotions.
Dealing with ML deployment challenges? Contact us for tailored MLOps solutions!
How does your team handle ML validation?
Appendix
Appendix A: Validation stage YAML
- stage: Validation
displayName: "Validation"
jobs:
- job: Validation
steps:
- bash: |
conda activate churn_prediction
python -m pytest tests/validation -vv --junitxml=validation_test_results.xml --val-model-version=$val_model_version --prev-month-preds=$prev_month_preds --curr-month-preds=$curr_month_preds
displayName: 'Run Validation Tests'
Appendix B: MAJOR/MINOR/PATCH examples
MAJOR - Breaking Changes
- Architecture changes (XGBoost → Random Forest, different input/output shapes)
- Feature schema changes that break backward compatibility with Evaluation phase.
- Add, remove, rename features
- Change type and feature logic
MINOR - Feature Updates
- Scheduled retraining with recent data (same features, same architecture)
- Performance metrics show material improvement
- Training methodology changes
PATCH - Maintenance Updates
- Non-functional changes (code refactoring, dependency updates)
- Everything else
Appendix C: Tech Stack
Built on Azure DevOps for orchestration (e.g., env var handling for secrets) and Snowflake for ML operations, leveraging Snowflake Model Registry for model versioning and deployment and Snowflake procedures and tasks for monthly refreshes automation.
Appendix D: Monitoring Notebook Monthly Output
| Feature | Metric (PSI/JSD) | Status |
|---|---|---|
| Feature 1 | 0.0052 | ✅ STABLE |
| Feature 2 | 0.212 | ⚠️ MODERATE DRIFT |
| Feature 3 | 0.322 | 🚨 HIGH DRIFT |
| … | … | … |